
BLOG
60% of Marketing Content Goes Unused And AI is About to Make it Worse
From $2.5 million wasted annually to 60% of marketing content never reaching a customer, here is what the numbers say about enterprise content strategy gaps.

CARBON™ turns weeks of custom ETL development into hours of YAML configuration. Define your sources, transformations, and targets in simple config files, and let PySpark pipelines handle the rest.
Your data engineering teams write custom ETL code for every new source system, every migration project, and every pipeline change. That manual effort creates bottlenecks, introduces inconsistencies, and delays analytics delivery by weeks or months. CARBON™ eliminates repetitive pipeline development with configuration-driven automation.
CARBON combines low-code YAML configuration, PySpark transformation libraries, and automated orchestration to deliver reliable data pipelines at scale.
We build dependable data pipelines using a low-code ingestion framework that replaces fragile, hand-coded scripts with configuration-driven processes for consistent and accurate data flow.
We automate the full ETL development cycle through YAML configuration, generating extraction, transformation, and load pipelines without repetitive custom coding.
We provide pre-built PySpark libraries for common data transformations, so your engineering teams focus on business logic rather than repetitive data plumbing.
We run CARBON on PySpark libraries and Spark runtime, giving your data pipelines the ability to scale horizontally with growing data volumes without re-architecture.
We streamline migrations from legacy data warehouses to modern cloud platforms, reducing transition timelines by more than half through pre-built connectors and configuration templates.
We integrate with Apache Airflow to automatically generate DAGs for pipeline scheduling, monitoring, and alerting.
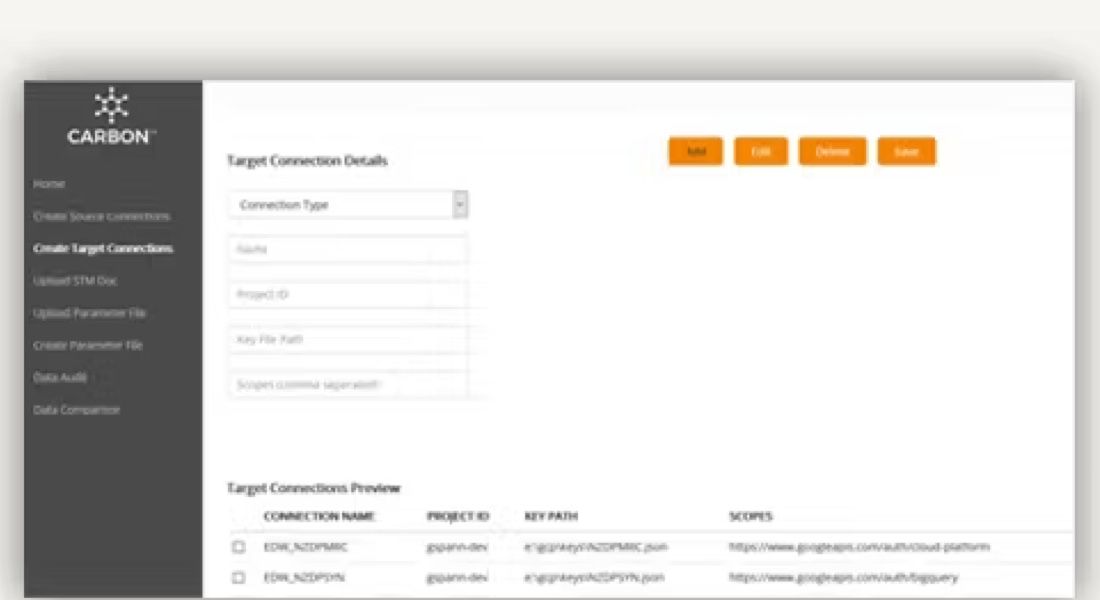
Define connectors, schema metadata, transformations, and column mappings in declarative YAML files.
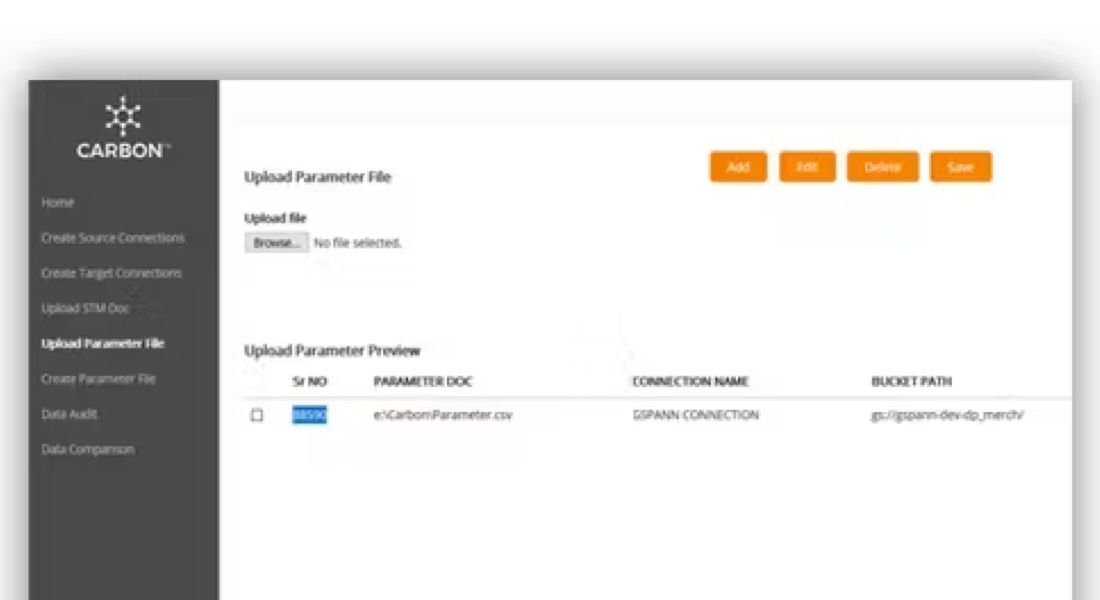
Access pre-built libraries that standardize common data transformations across all pipelines.
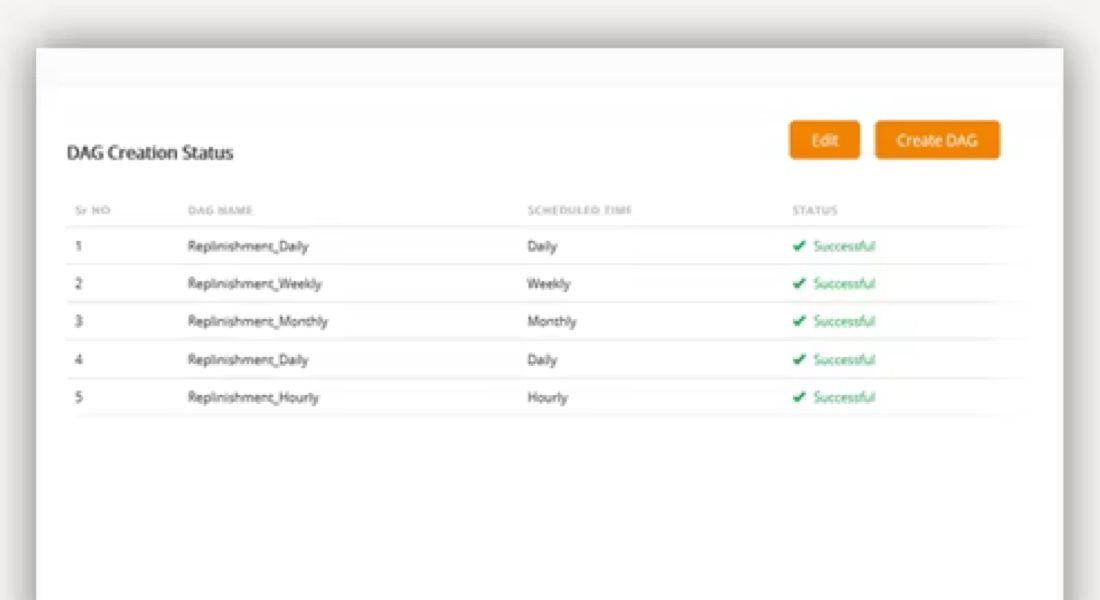
Generate DAGs automatically from your YAML configuration, eliminating manual orchestration setup.
Automate all ETL stages from extraction through transformation to loading in target platforms.
AI-powered CDP accelerator that consumes CARBON data feeds to build unified customer profiles from multiple enterprise sources.
Learn more →Automated ETL testing tool that validates data quality across CARBON pipelines, ensuring accuracy at every stage from source to target.
Learn more →Testing and data quality accelerator that provides the observability and validation framework underlying CARBON pipeline monitoring.
Learn more →Schedule a walkthrough to see how CARBON automates pipeline development and accelerates your migration to modern data platforms.




