
BLOG
60% of Marketing Content Goes Unused And AI is About to Make it Worse
From $2.5 million wasted annually to 60% of marketing content never reaching a customer, here is what the numbers say about enterprise content strategy gaps.

BEAT™ automates data testing, profiling, and health monitoring across your pipelines and repositories. Catch quality issues during sprints, not after production failures, and give your data engineering team continuous visibility into data health.
Your data pipelines are only as reliable as the validation behind them. When errors slip through undetected, they cascade into flawed reports, misguided decisions, and costly downstream failures. Manual data testing cannot keep pace with the volume and velocity of modern data flows. BEAT™ solves this by automating validation across the entire data lifecycle.
BEAT delivers end-to-end data quality automation from test design through production monitoring.
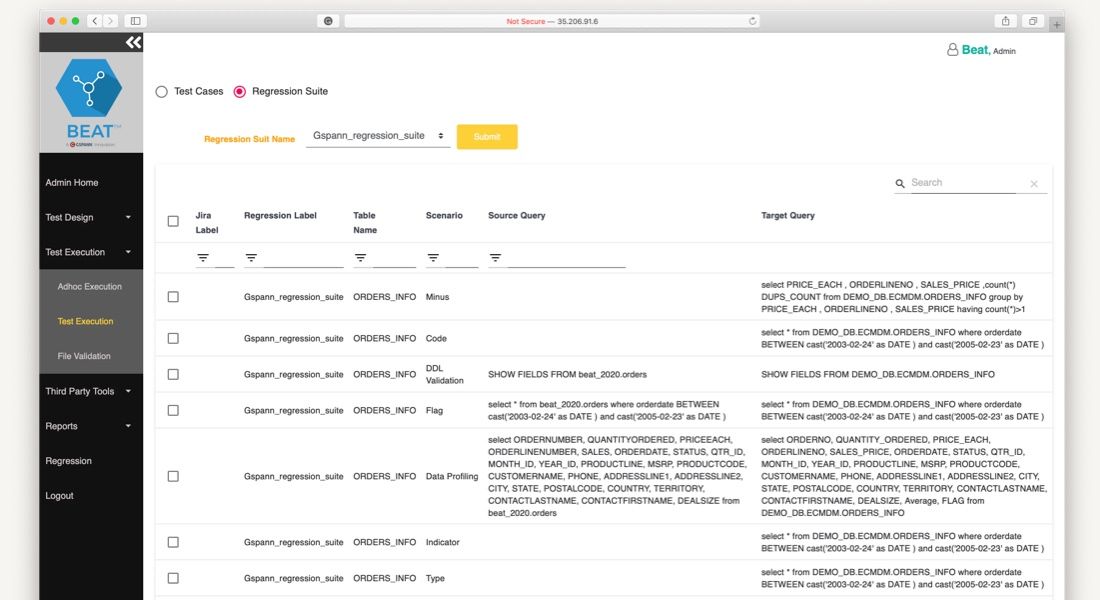
We implement and execute comprehensive tests for your data pipelines, data products, and BI reports. BEAT runs in-sprint and regression tests automatically, catching errors before they reach production.
We monitor your production data health continuously, recording trends over time and triggering alerts when predefined thresholds are breached.
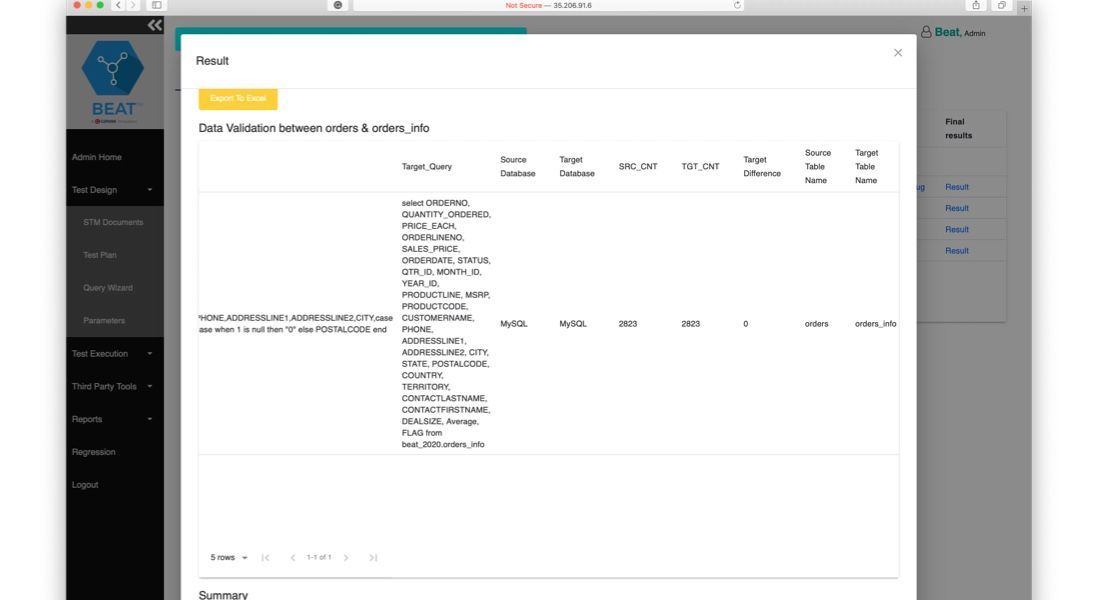
We analyze your data sources at the field and column level to discover anomalies, inconsistencies, and structural issues that standard queries miss.
We provide tailored interfaces for every role in your data quality workflow. Administrators configure rules, test designers build validation scenarios, execution teams run tests, and monitors track outcomes.
We generate automated metrics on test coverage, pass/fail rates, and execution trends that serve as an early warning system for quality degradation.
We connect BEAT directly to Jira and Confluence so failed tests create tickets automatically, audit reports publish to your knowledge base, and your teams resolve issues within existing workflows.
Tests across data pipelines, data products, and BI reports in a single platform.
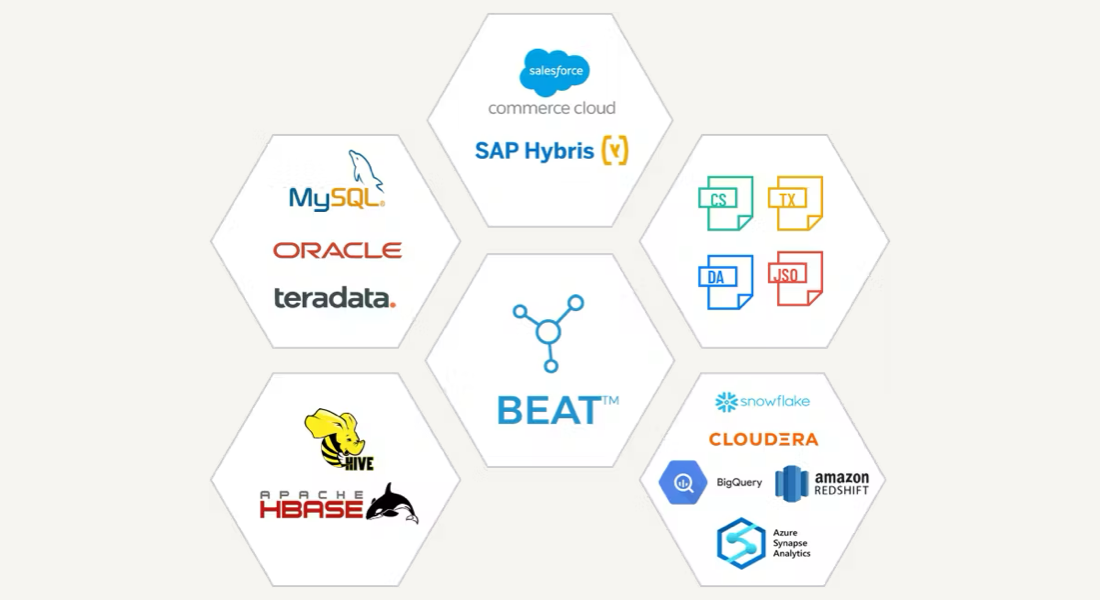
Connects directly to your existing ETL toolchain with native connectors.
Triggers alerts when data health falls below defined thresholds.
Creates tickets automatically for failed tests with full context and error details.
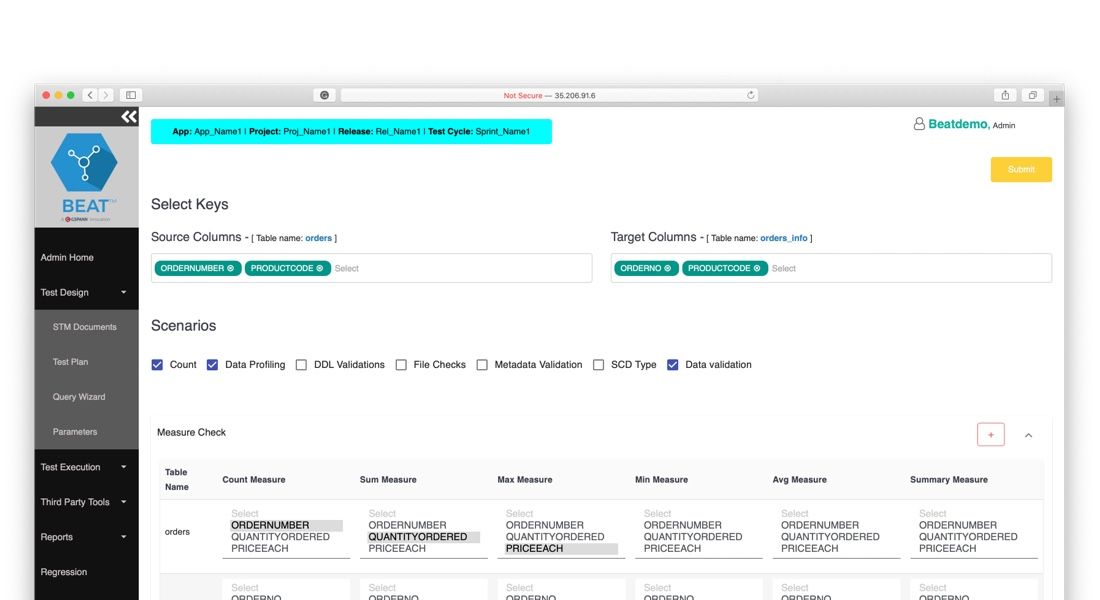
Simplifies test case creation through template-based design and reusable validation components.
AI-powered CDP accelerator that depends on BEAT for validated source data before ingesting customer records into unified profiles.
Learn more →Configurable big data ingestion engine that handles high-volume data feeds, with BEAT validating data quality at each stage.
Learn more →Testing and data quality framework that provides the foundational observability layer BEAT extends with automated data-specific validation.
Learn more →Schedule a walkthrough to see how BEAT validates your data pipelines, automates testing, and delivers continuous data health monitoring for your team.




