Effective management of data is essential for maximizing its value. It involves organizing and storing data to make it easily accessible and usable. By paying careful attention to data ingestion, you can ensure your data is clean, organized, and ready to be used to its full potential.
This white paper describes three approaches to building a solid data ingestion pipeline. The three approaches involve various combinations of Apache Spark, Amazon EMR, Databricks, and Databricks Notebook.
Data Ingestion Pipelines
Data ingestion is the process of collecting data from various sources - such as databases, applications, and websites - and transforming it into a usable format. From a business perspective, an effective data ingestion pipeline allows for timely and accurate collection of data to be efficiently analyzed to gain insights and make informed decisions. This drives strategic planning and operational efficiency while ensuring that all stakeholders have access to the most up-to-date information.
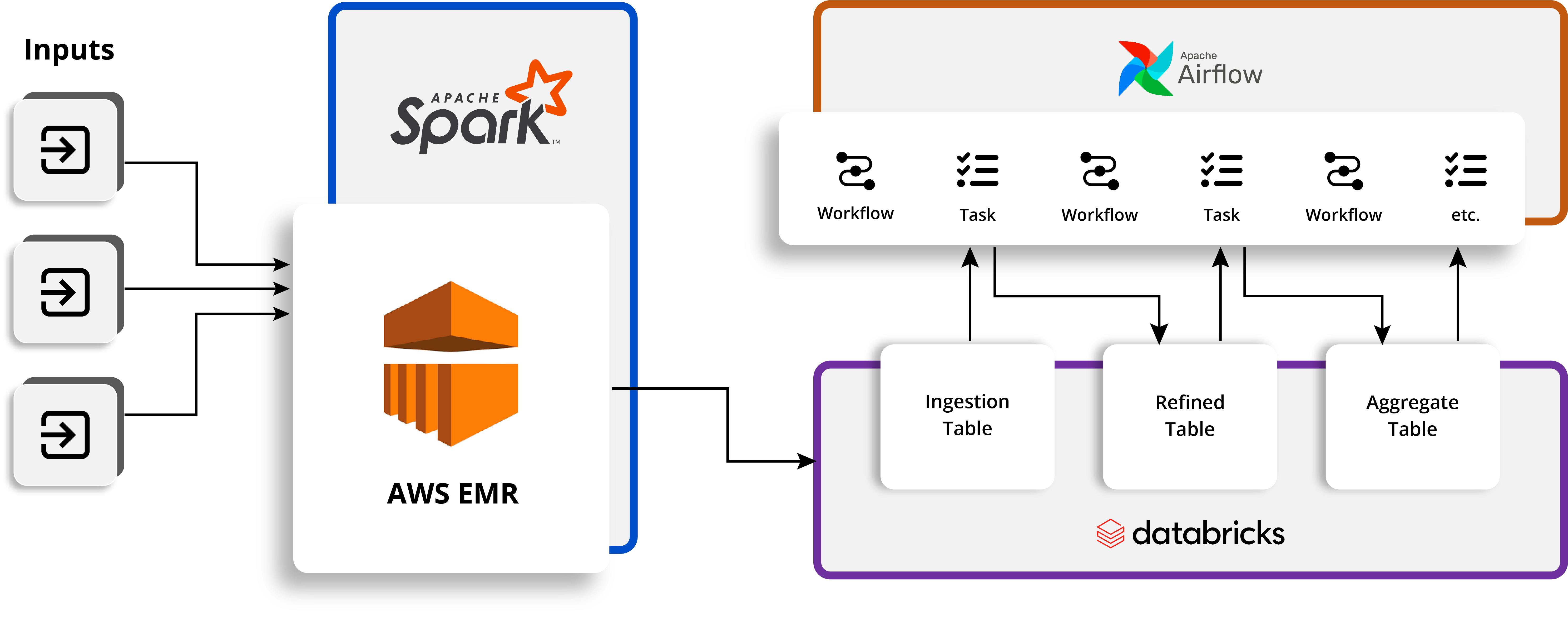
Managed Spark
Managed Spark is a service that simplifies creating and managing Apache Spark clusters. It provides users with an easy-to-use interface and tools to set up and manage their clusters and monitor performance quickly. Managed Spark also offers proactive management, allowing users to automatically scale up or down their clusters based on their workloads, reducing operational costs and complexity. Ultimately, Managed Spark makes using Apache Spark easier and more efficient.
Amazon EMR
Amazon EMR is a managed service from Amazon Web Services that provides computation, analytics, and storage using Amazon's distributed computing platform. It enables users to quickly spin up clusters of computers to perform computation, analyze big data sets, and even run distributed applications. Amazon EMR also offers web interfaces that make working with the platform a breeze and provide an end-to-end data science and analytics experience. With Amazon EMR, users can focus on developing data science applications and not worry about the infrastructure or the underlying hardware.
Databricks
Databricks provides a comprehensive and powerful real-time platform to analyze and process data. You can use Databricks to store, organize, and analyze your data, enabling you to gain insights, increase efficiency, and make smarter, data-driven decisions. With the power of Databricks, you can easily create data pipelines. The pipelines can incorporate machine learning models and advanced analytics to help you better understand your customers.
Databricks Notebook
Databricks Notebook is an interactive platform for data scientists and engineers to collaborate on code development and analytics. Users can write, run, and share code in a notebook-style interface. It supports various programming languages, such as Python, R, Scala, and SQL, with rich visualizations and powerful integrations. Its collaborative environment allows you to easily share and manage notebooks, track and debug code, and scale up your projects for production with its cloud platform.
What You Will Learn
This white paper covers important topics like:
- How to get started building a data ingestion pipeline
- Managed Spark with Amazon EMR
- Managing Spark with Databricks
- How to manage an ingestion pipeline using Databricks Notebook
The last section of the white paper provides an excellent summary comparing the three approaches side-by-side. Building a solid strategy for dealing with data at its source is vital for the continued success of your business.
Download this white paper and get started right away.

Srabani Malla
Sr. Technical Lead - IA
Published May 08 2023




