Apache Solr is exceptionally reliable, scalable, and fault-tolerant. It provides everything from distributed indexing, replication, and load-balanced queries to centralized configuration, and automated failover and recovery. Solr powers the search and navigation features of many of the world's largest internet sites.
What many companies fail to recognize, however, is that an improperly configured Solr cloud can quickly cause costs to soar. By taking advantage of the best practices featured in this blog, you can achieve top-notch performance while saving costs.
Indexed Fields
You can save your company a considerable amount of money in storage and cloud usage fees by controlling the number of index fields you incorporate in your search implementation. Indexing represents a trade-off between quality, performance, and cost. It is important to note that creating too many indexes may end-up degrading performance while increasing costs. The best strategy is to choose minimum number of indexes to support your performance target.
The number of indexed fields increases the following:
- Memory usage while indexing
- Segment merge times
- Optimization times
- Index size
Do not mark fields as indexed=true if they are not used in a query.
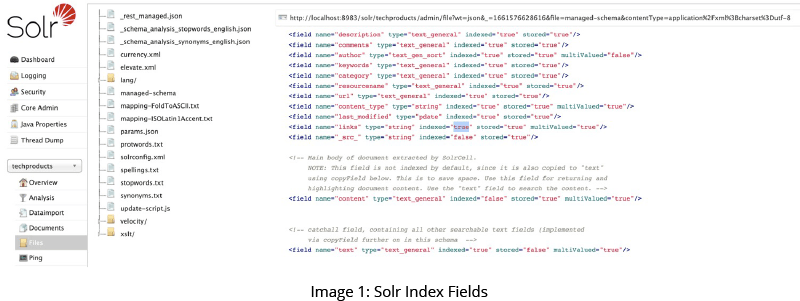
Stored Fields
Retrieving stored fields of a query result can be a significant expense. This cost is affected by the number of bytes stored per document. The higher the byte count, the sparser the documents will be distributed on disk - which requires more I/O bandwidth to retrieve the desired fields.

These costs start to add up on cloud-based implementations. As with index fields, however, you are again confronted with a trade-off between quality, performance, and cost. As you define more stored fields, performance improves, but you incur higher costs.
Utilizing Solr Cache
Solr caches several distinct types of information to ensure that similar queries do not repeat work unnecessarily. There are three major cache types, as summarized in Table 1.
| Cache Type | Description |
|---|---|
| Query Cache | Stores sets of document IDs returned by queries |
| Filter Cache | Stores filters built by Solr in response to filters added to queries |
| Document Cache | Stores the requested document fields when showing query results |
Here is a little bit more information on Document Cache. When asking Solr to search, you may request one or more stored fields to be returned with your results. Document Cache helps in improving the time required to service subsequent requests, including the same document.
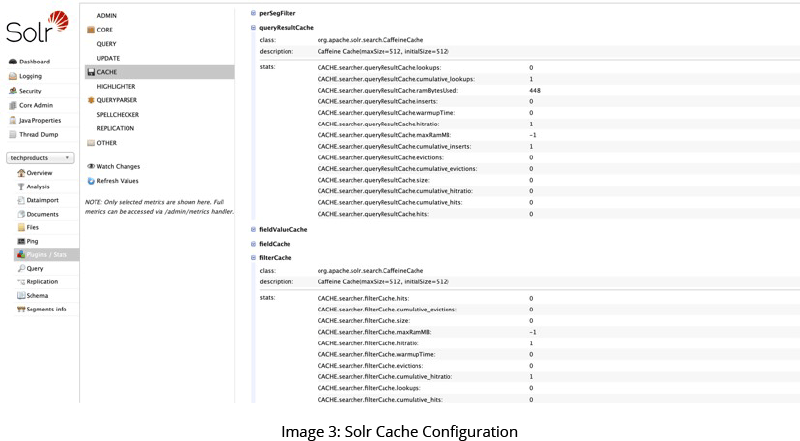
Configure Cache Autowarm
You can give your search performance a tremendous boost by activating ‘autowarming’ for any or all three types of cache (see Table 1). By increasing the autowarmCount configuration setting, you instruct Solr to pre-populate or ‘autowarm’ its cache with cache objects created by the search results process. The autowarmCount is the number of cached items that will be copied into the new searcher.

Streaming Expressions
Solr offers a simple yet powerful stream processing language for Solr Cloud. Streaming expressions are a suite of functions that can be combined to perform many parallel computing tasks. These functions are the basis for the Parallel SQL Interface.
The example shown here dumps all rows from ‘some_collection’ and allows parallel processing of data using ‘year’ as the partition key.
expr=search(some_collection,
zkHost="https://solr.gspann.com:9999",
qt="/export",
q="*:*",
fl="id,name,addr,status,year,month,day",
sort="year desc, name asc",
partitionKeys="year"
) JVM Memory Heap Settings
The Java Virtual Machine (JVM) memory heap is an efficient pool of memory used by Java to store objects created by Java applications at runtime. The Java Virtual Machine (JVM) memory heap settings affect system resource utilization. In a cloud environment resource usage is metered and costs can quickly add up. In addition, these settings impact performance and directly affect the success or failure of your search implementation.
Adding Enough Headroom
Various tools, including jconsole, usually included with standard Java installations, show minimum amount of memory consumed by the JVM when running Solr. If you do not allocate enough memory to the heap, the JVM can cause heightened resource consumption due to the ‘garbage collection’ process running too often. We recommend adding an additional 25% to 50% over the minimum required memory to operate at peak performance.
OS Memory
At first, you might be inclined to allocate as much memory as possible to the JVM memory heap. You need to exercise caution because Solr makes extensive use of the org.apache.lucene.store.MMapDirectory component. This technology leverages the operating system (OS), and, by extension, CPU memory management.
As part of its normal operation, Solr maps file into memory that is drawn from the OS kernel, and not from the memory heap used by the JVM. You should strive to minimize the amount of memory allocated to the JVM memory heap to free OS memory, which is used by the ‘MMapDirectory’ component.
Yes, this is contradictory advice, but it’s important to recognize that the more memory you allocate to the JVM memory heap, the less memory there is available to the OS. If Solr indexing suffers, search performance suffers as well. It’s important to strike a balance between the JVM memory heap and OS memory.
What Should be the JVM Memory Heap Size?
A range of 8 to 16 GB is common. It’s best to start with the smaller value and run tests while monitoring memory usage. Gradually tune the heap size up until you achieve optimal performance. The more extensive your tests, the better your chance of a successful deployment.
Garbage Collection
‘Garbage collection’ is the term that refers to the process where memory freed up in a Java program is returned to the general memory pool for re-use. Over the years, there has been considerable improvement in garbage collection components. The legacy garbage collector used prior to Java version 9 was ParallelGC. The G1GC garbage collector operates in a concurrent multi-threaded fashion and addresses latency issues encountered in ParallelGC. Thus, our team recommends that if you are using Java 9, make sure to use the G1GC garbage collector.
Conclusion
The key takeaway from this article is that when it comes to Solr search, it’s important to strike a balance between quality, performance, and cost. Finer quality can be achieved by manipulating indexed and stored fields.
Higher performance comes by configuring Solr cache, auto warming, using streaming expressions, and allocating memory. High quality and performance can translate to higher costs due to memory, resource, and bandwidth usage. You can achieve optimal search by carefully monitoring memory, resource, and bandwidth usage as you conduct extensive testing using a large volume of realistic data.

Navaneeth Aripekatta Kocha
Practice - Application Development
Published Mar 07 2023





