Leverage CARBON™ to Rapidly Accelerate Ingestion of Data into Big Data Platform
Migration of data to seed data lake is a huge task, requiring a lot of development cycles to build the pipelines, and put auditing and error checking in place. CARBON automates the source metadata identification, builds the pipeline, including the deployment dags, based on the source (file, database, service or stream) with error checking and audit functionality.
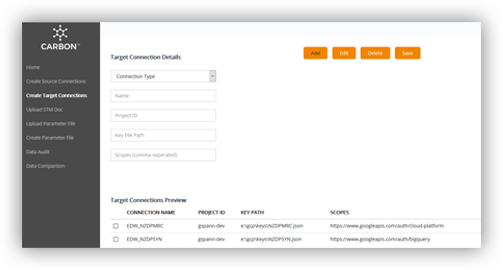
Migrating from Teradata or Legacy data warehouse to Big Data solution?
Building the future state Enterprise Data and Analytics platforms on Big Data on cloud or in-premises technology stack is a great vision. But, firstly, this needs a major as-is legacy state understanding and secondly, needs lots of hours of rebuilding the pipelines. CARBON provides you the way which reduces the cost while shrinking the time to market for building parallel pipelines to build staging layer from the sources feeding legacy EDW. It does so by automating the understanding of the source, auto generating the incremental code.
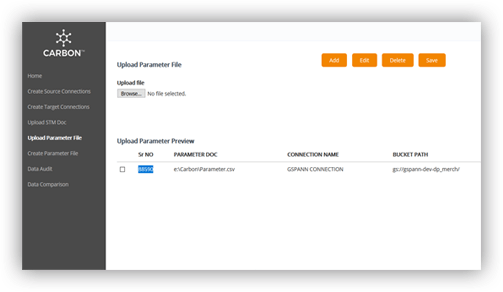
Automated generation of AirFlow dags
Building the MFT or Sqoop jobs is one step but then you have to recreate all the schedules for these data ingestion jobs. This in itself is an extremely time consuming process. CARBON gives you the capability of auto generating the associated Airflow dags for the data ingestion jobs. The total time taken to build a job that ingests the data into raw or stage layers in the Big Data platform stack shrinks from weeks to hours. Let us help you accelerate the building of your Big Data and Analytics Platform of the future.
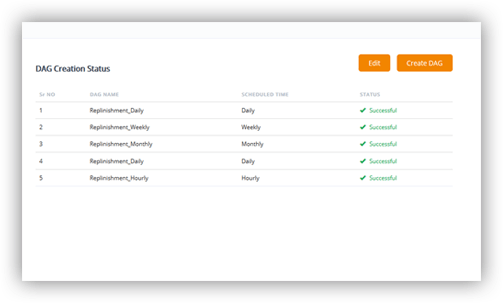
Data Quality validation of migration jobs
Ensuring sanctity of data post deployment is critical for business adoption of your Big Data platform. Trust in data needs to be cultivated. Data validation is more than testing during development phase. The approach recommended is to generate the data validation scores post production runs. CARBON integrates with BEAT to provide the hooks and checks to ensure quality consistency of both data and business KPI.